Work Packages
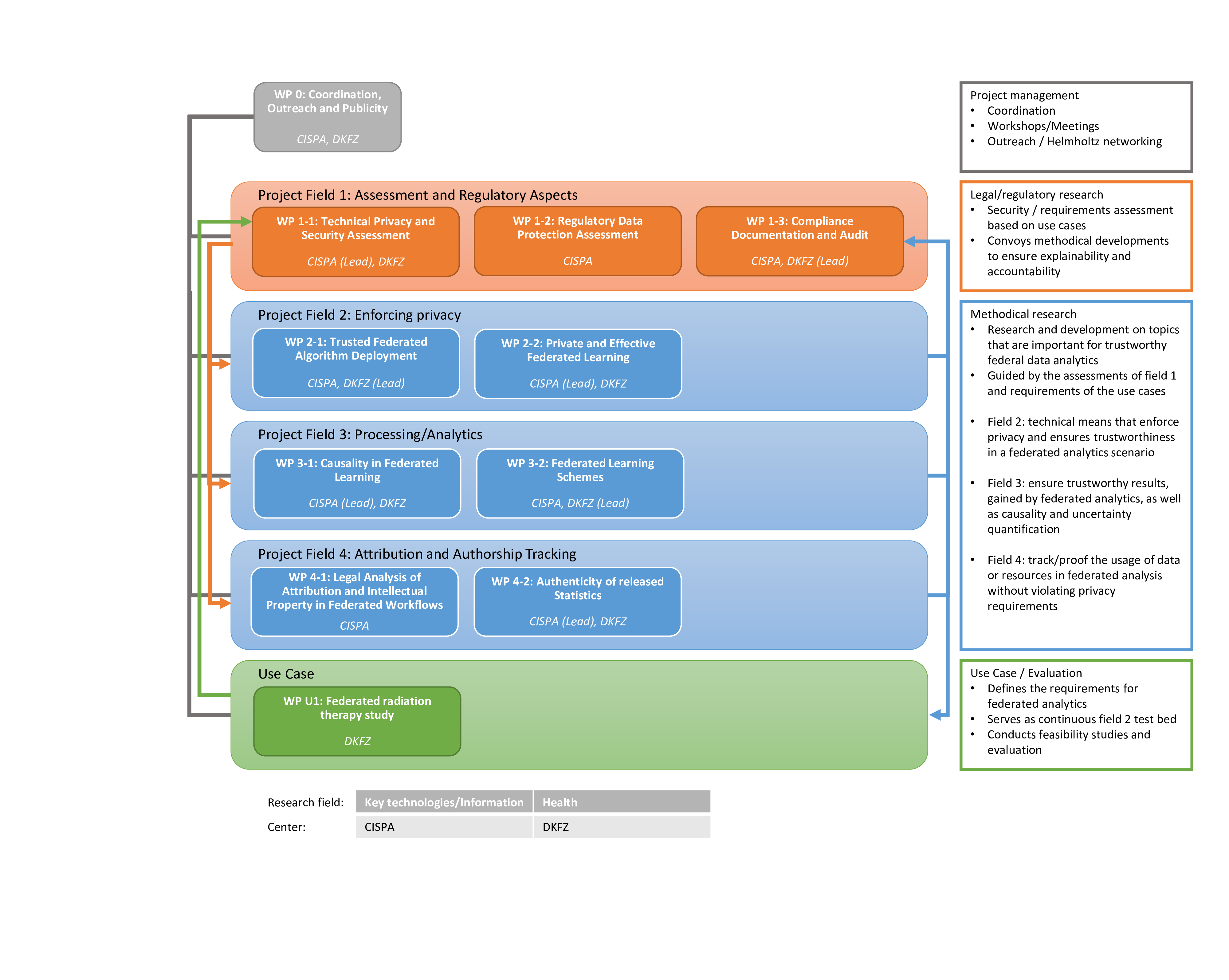
Assessment and Regulatory Aspects
Work Package 1-1: Technical Privacy and Security Assessment (Lead: Yang Zhang)
Federated learning is designed with the security and privacy in place as users’ data never leave their own sites. However, recent work shows that the federated setting introduces other attack surfaces which can be exploited by adversaries. Until now, we lack a thorough understanding of the security and privacy risks in specific federated learning settings. Therefore, we plan to perform a comprehensive assessment mainly from two different perspectives: model security and data privacy. For model security, we plan to investigate the feasibility of the joint learned model being stolen or replicated with respect to functionality and architecture. For data privacy, we concentrate on multiple angles of possible data leakage, such as data attribute prediction, membership inference, and training data distribution estimation. All the planned studies will be carried out in both active and passive adversarial settings. This enables us to achieve a comprehensive assessment of the system before it is enhanced with novel defense techniques and deployed in the real world.
Work Package 1-2: Regulatory Data Protection Assessment (Lead: Ninja Marnau)
The utilization of novel data processing designs introduces friction with regard to legal requirements for the processing of personal data. Although the General Data Protection Regulation (GDPR) is a comparably new legal framework, it is mostly technology-neutral and tailored for centralised data processing. The guarantees offered by federated approaches and privacy-enhancing methods such as Differential Privacy come with probabilistic privacy notions and guarantees that are subject to an adversary’s capabilities. These computer science notions are incongruous with the legal notions e.g. of anonymity in recital 26 GDPR.We will analyse how these novel secure and privacy-friendly data science solutions relate to the GDPR’s requirements and how federated collaboration relates to the legal roles of (joint) controllers and processors. We aim to outline and explain, in which way technological solutions enable joint data science even for sensitive data such as health information or substitute conservative organisational or contractual measures.
The legal analysis will lay the groundwork to make these novel security- and privacy-by-design approaches “explainable” to the competent data protection supervisory authorities and certification bodies.
Work Package 1-3: Compliance Documentation and Audit (Lead: Martin Lablans)
Based on the insights of WP 1-1 and WP 1-2, we will author documents that can be used to explain federated analysis concepts, guarantees and limitations to domain experts and support its adoption by future project and collaboration ideas. In addition this WP ensures the update and extension of the documents based on the scientific insights and technical advancements achieved by the following WPs in the course of the project. This work package also comprises the discussion with and approval by the health-specific regulatory authorities.
Enforcing Privacy
Work Package 2-1: Trustworthy Federated Algorithm Deployment (Lead: Ralf Floca)
In the scenario of federated analytics it is necessary to ensure the deployment of analytical methods to computational sites and data owners in a trustworthy, traceable and secure manner. This comprises, amongst others questions , (i) how to ensure origin and content of provided algorithms; (ii) how to provide traceability of responsibility for provided algorithms; (iii) how to map requirements and guarantees between data owner, computational resource provider and algorithm provider; (iv) how to monitor and/or enforce compliance to these guarantees; (v) how to offer mechanisms for bi- or multilateral usage agreements.
We plan to develop services needed to establish a customizable infrastructure for trustworthy federated analytics, which will, e.g., support and ensure algorithm authenticity, compliance with resource and bandwidth agreements and security promises according to different levels based on assessment concepts developed in W1-1. We will base them on modern cloud and containerization technologies (like Helm, Harbor, Notary) to ensure fast prototyping and a good generalizability. The system architecture will also consider existing efforts to use synergies and increase interoperability. All newly developed services and all service deployment templates will be provided as open source in order to allow the instantiation of federated analytics for other projects and domains.
Work Package 2-2: Private and Effective Federated Learning (Lead: Mario Fritz)
Differential privacy provides methods to protect the privacy of data in federated learning scenarios. Data or messages are sanitized by perturbation with calibrated noise in order to remain within a provided privacy budget. However, this comes with inherent tradeoffs between privacy and utility of the learning algorithms. In addition, the dependency between privacy parameters and utility as well as the protection against specific attack vectors is unclear. Therefore, we quantify utility for relevant federated learning scenarios in the medical domain as well as investigate techniques to improve the utility of such algorithms. Furthermore, we will conduct empirical studies that connect differential privacy with inference attacks such as membership inference and then seek analytical solutions that provide defenses against such attack vectors. In order to make such approaches more practical, we will investigate how black box algorithms or update schemes can be made differentially private, e.g. by constructing synthesized data sets so that guarantees on differential privacy are inherent.
Processing / Analytics
Work Package 3-1: Causality in Federated Learning (Lead: Jilles Vreeken)
While data mining and machine learning techniques have made great progress in past years, many of these pick up mere associations rather than discovering the true significant causal structure behind the data. We advance state of the art in discovering causal models from large quantities of medical and geospatial data, with special focus on efficiently and reliably accounting for batch effects within distributed and federated settings, determining the practical and theoretical bounds of their performance in these resource-constrained settings compared to the ideal centralized algorithm.
Work Package 3-2: Federated Learning Schemes (Lead: Klaus Maier-Hein)
There are different schemes that can be followed in federated learning, each of them with their own risks and benefits. Example for possible schemes are (a) local model training and incremental or final update/combination into a central model; (b) variations of institutional incremental learning, where the model is passed around and trained sequentially on site; or (c) learning from generative models that are trained locally.
In this work package we will systematically analyse and evaluate the different multi-institutional learning schemes and assess their potential for the different research use cases with respect to the associated risks and benefits. Besides the performance (e.g. prediction quality) this analysis will also cover the quantification of result uncertainties associated with the different schemes and, in conjunction with WP 2-2, effects of mitigation strategies for security risks (e.g. differential privacy) applied to the learning schemes. With respect to the learning scheme there are different methodically challenges (e.g. quantification and representation of uncertainties in example (a) or additional threat vectors in example (b)) that we also will tackle in this work package.
Attribution and Authorship Tracking
Work Package 4-1: Legal Analysis of Attribution and Intellectual Property in Federated Workflows (Lead: Ninja Marnau)
Federated and joint data science raises several new challenges with regard to fair attribution, licensing and intellectual property rights. If there is legal uncertainty in whether their contribution to the results (be it raw data, annotation, algorithms, models, training, or knowledge extraction) get acknowledged, scientists will be hesitant to participate in federated workflows. Currently it is mostly unclear what (intellectual) property rights would apply to processes of federated data science. The protection of property-equivalent rights for data (“data ownership”) as well as machine learning algorithms and results is highly debated and not internationally harmonised. We will analyse which intellectual property regimes and institutes (e.g. patents, trademarks, copyright) apply during steps of the federated process and the multilateral cooperation, and which legal thresholds need to be met in order to fairly attribute and enforce intellectual property rights throughout the process.
Work Package 4-2: Authenticity of Released Statistics (Lead: Nico Döttling)
There are natural scenarios in which it is necessary to provide evidence or a proof that a certain analysis result (e.g. statistic or trained model) has been computed from a specific dataset. For instance, this would on one hand enable a group of research collaborators to share credit proportionally to how much the data they contributed influenced the joint findings. On the other hand this is also needed in a regulatory context (e.g. to see where the data of a patient has been used). In another scenario authenticity needs to be guaranteed from its source to the final result and be resilient to adversarial manipulation and data injection at every step. This is important in settings with political or medical impact, e.g. making therapeutic decisions.
Succinct non-interactive arguments enable this form of authentication in a generic way. We will investigate authentication primitives and succinct argument systems which lend themselves to the continuous methods (e.g. gradient descent) typically employed by machine learning algorithms. Complementary to this effort, we will investigate whether there are natural scenarios in which training datasets and/or trained models can be fingerprinted, such that e.g. neural networks can be linked to specific datasets that were used for training.
Use Case
Work Package U1: Health - Federated Radiation Therapy Study (Lead: Michael Baumann)
This work package represents the use case from health research and has 3 major objectives: 1) ensure high generalizability of the project results by helping to establish a comprehensive requirements engineering and risk assessment; 2) offer a testbed throughout the project duration to evaluate developed concepts with a rapid turnaround cycle; 3) validate the concept of trustworthy federated analysis compared to already conducted analysis on pooled data.
In the health research sector, sharing and pooling of data is particularly challenging. Nevertheless it is especially important in the context of personalized medicine, which requires large consortia to reach the necessary cohort sizes to reach conclusive results. Thus networks like the German Cancer Consortium (DKTK) have been created. DKTK successfully established partnership between more than 20 academic research institutions and university hospitals with the DKFZ as the consortium’s core center. Despite its success, even in such an elaborate network, pooling data is still a challenge. Having the technical means to employ a federated analysis concept that circumvents the necessity to pool the original data and instead allows to exchange and merge less sensitive analysis results would be extremely beneficial.
We will showcase the developed methodology by revisiting a successful radiation therapy study and reanalyze the data using a federated scenario with the original, distributed source data sets. This will allow us to validate the federated analysis in comparison to the results of the previous, pooled analysis. In addition, if successfully validated, we will use the developed techniques to extend and update the study by new, still unpooled data. To showcase integration of the new methods with existing domain-specific technologies and infrastructures and to achieve a quick project progress, support subsequent use and dissemination, we will utilize existing infrastructures, namely the DKTK “bridgeheads” for clinical data and federation functionality (e.g. pseudonymization, usage agreements) and the DKTK Joint Imaging Platform for imaging data and execution with GPU-backed compute resources.